[Announcement of Publication] In July 2021, our paper presented at the conference of Medical Imaging with Deep Learning (MIDL) was published in the Proceedings of Machine Learning Research – A pivotal investigation of Fundamental Technology for Transfer Learning-
Medmain Inc. (Headquarters: Fukuoka City, Fukuoka Prefecture, CEO: Osamu Iizuka, hereinafter “Medmain”), a provider of “PidPort” pathological diagnosis support solutions, has confirmed that it is now possible to perform faster transfer learning approach by fine-tuning the batch norm parameters leads to demonstrate a pivotal and fundamental technology for deep learning.
DOI: https://openreview.net/forum?id=TjwDWRdfZpg
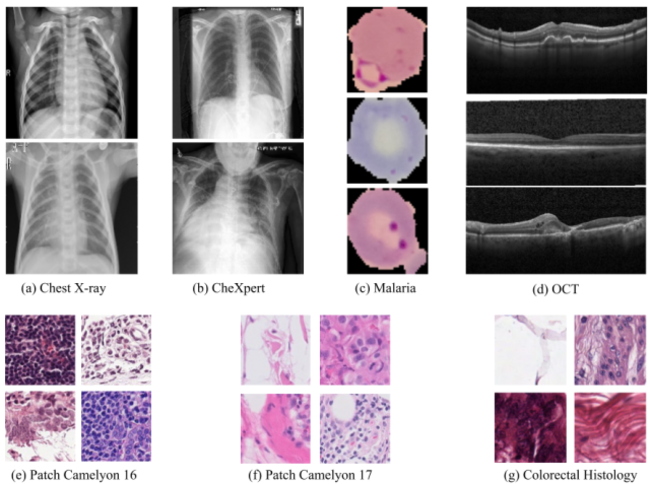
Transfer learning from ImageNet is the go-to approach when applying deep learning to medical images. The approach is either to fine-tune a pre-trained model or use it as a feature extractor. Most modern architecture contain batch normalisation layers, and fine-tuning a model with such layers requires taking a few precautions as they consist of trainable and non-trainable weights and have two operating modes: training and inference. Attention is primarily given to the non-trainable weights used during inference, as they are the primary source of unexpected behaviour or degradation in performance during transfer learning. It is typically recommended to fine-tune the model with the batch normalisation layers kept in inference mode during both training and inference. In this paper, we pay closer attention instead to the trainable weights of the batch normalisation layers, and we explore their expressive influence in the context of transfer learning. We find that only fine-tuning the trainable weights (scale and centre) of the batch normalisation layers leads to similar performance as to fine-tuning all of the weights, with the added benefit of faster convergence. We demonstrate this on a variety of seven publicly available medical imaging datasets, using four different model architectures.